BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
The Intuition: Why We Need BLIP-2
The world of AI in the early 2020s was marked by a significant trend: the meteoric rise of Large Language Models (LLMs) like GPT-3, PaLM, and LLaMA. These models, trained on vast text corpora, demonstrated astonishing capabilities in understanding, reasoning, and generating human-like text. Concurrently, vision-language (VL) models like the original BLIP, while powerful, faced a critical challenge: prohibitive training costs.
The standard paradigm for VL models was end-to-end pre-training of the entire architecture—both the vision encoder and the language model components. As state-of-the-art LLMs grew to hundreds of billions of parameters, creating a vision-language model of a similar scale by training it from scratch became computationally and financially infeasible for most researchers. This created a bottleneck for progress.
This is the problem BLIP-2 was designed to solve. The core intuition is both simple and profound:
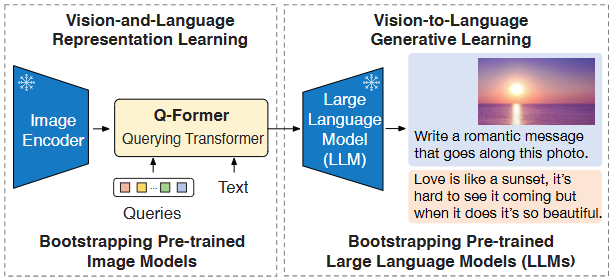
Fig.1 Overview of BLIP-2’s framework. We pre-train a lightweight Querying Transformer following a two-stage strategy to bridge the modality gap. The first stage bootstraps vision-language representation learning from a frozen image encoder. The second stage bootstraps vision-to-language generative learning from a frozen LLM, which enables zero-shot instructed image-to-text generation (see Figure 5 for more examples).
Instead of building a massive, monolithic vision-language model from scratch, can we leverage the power of existing, pre-trained, frozen models and teach them to work together?
BLIP-2 proposes to act as a “smart translator” or “bridge” between a powerful, off-the-shelf frozen image encoder and a powerful, off-the-shelf frozen LLM. The key insight is that the most expensive components (the vision backbone and the LLM) already contain immense knowledge. The challenge is not to re-learn this knowledge, but to bridge the “modality gap” between them. By training only a small, lightweight bridging module, BLIP-2 drastically reduces the number of trainable parameters and the overall pre-training cost, making state-of-the-art vision-language modeling more accessible and efficient.
This “bridging” component is the heart of BLIP-2: the Querying Transformer (Q-Former).
The BLIP-2 Model Structure: A Symphony of Three Components
The BLIP-2 architecture is a masterclass in modularity, composed of three main parts:
-
A Frozen Image Encoder: This is a standard, pre-trained vision model whose job is to extract visual features from an input image. The original work uses a Vision Transformer (ViT-L/14 from CLIP), but any powerful vision model could work. Crucially, its weights are frozen during the entire pre-training process. It acts solely as a feature provider.
-
A Frozen Large Language Model (LLM): This provides the language understanding and generation capabilities. BLIP-2 was tested with decoder-based LLMs like OPT and encoder-decoder LLMs like Flan-T5. Like the image encoder, the LLM’s weights are also frozen. It brings its vast linguistic knowledge to the table without needing to be retrained.
-
The Querying Transformer (Q-Former): This is the lightweight, trainable module that connects the two frozen giants. The Q-Former is a cleverly designed transformer model tasked with a single, critical job: to extract visual features from the frozen image encoder that are most relevant to the text. It acts as an information bottleneck, distilling the rich, high-dimensional visual information into a few concise feature vectors that the LLM can understand.
Let’s look closer at the Q-Former. It contains two main sub-modules that share the same self-attention layers:
- Learnable Query Embeddings: The Q-Former introduces a fixed number (e.g., 32) of learnable embedding vectors. These queries are persistent and are not tied to any specific input. Think of them as a set of “questions” the model learns to ask about the image.
- Image Transformer: This module interacts with the frozen image encoder. Its learnable queries interact with the image patch embeddings via cross-attention to extract visual features.
- Text Transformer: This is a standard BERT-style text encoder-decoder. It can function as both a text encoder (understanding) and a text decoder (generation).
The brilliance of the Q-Former lies in its attention mechanisms. The learnable queries can attend to the image patches (via cross-attention), they can attend to each other (via self-attention), and they can attend to input text (via the same cross-attention layers). This allows them to become a flexible representation of the visual scene, conditioned by text when available.
Let’s clarify: The Q-Former is a single, unified transformer.
It is not a Siamese network with two parallel streams. Instead, think of it as a single transformer that processes a concatenated sequence of two different types of tokens: the learnable queries and the input text tokens. The “submodule” concept refers to the different operations that are applied to these two types of tokens as they pass through the single transformer architecture.
- The “image transformer” submodule refers to the operations involving the learnable queries and their interaction with the frozen image encoder’s features via cross-attention.
- The “text transformer” submodule refers to the operations involving the text tokens.
Because they are processed as one long sequence in the self-attention layers, they can interact. The degree and direction of this interaction are precisely controlled by the attention masks.
Mathematical and Algorithmic Explanation
Let’s define the inputs and their dimensions, following the paper’s examples.
- Frozen Image Features ($I$): The output of the frozen image encoder (e.g., ViT-L/14).
- $I \in \mathbb{R}^{B \times N_p \times D_\text{img}}$
- $B$ = Batch size
- $N_p$ = Number of image patches (e.g., 257)
- $D_\text{img}$ = Dimension of image features (e.g., 1024)
- Learnable Queries ($Q_\text{learn}$): A set of trainable embeddings that are part of the Q-Former’s parameters.
- $Q_\text{learn} \in \mathbb{R}^{N_q \times D_q}$
- $N_q$ = Number of queries (e.g., 32)
- $D_q$ = Hidden dimension of the Q-Former (e.g., 768, for BERT-base)
- Input Text Embeddings ($T$): The standard token embeddings of the input text.
- $T \in \mathbb{R}^{B \times N_t \times D_q}$
- $N_t$ = Number of text tokens
- $D_q$ = Hidden dimension (must match queries, e.g., 768)
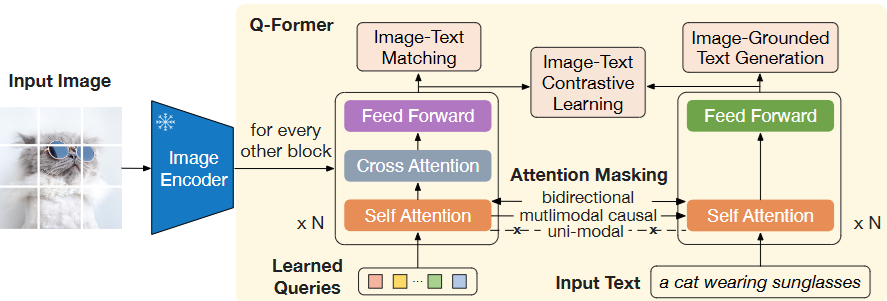
Fig.2 Model architecture of Q-Former and BLIP-2’s first-stage vision-language representation learning objectives. We jointly optimize three objectives which enforce the queries (a set of learnable embeddings) to extract visual representation most relevant to the text.
Inside a Q-Former Block
A Q-Former block consists of a Self-Attention layer, a Cross-Attention layer (which is only applied to the queries), and a Feed-Forward Network (FFN). Let $H_q$ and $H_t$ be the query and text representations entering the block.
1. Self-Attention (The Core Interaction):
The queries and text are concatenated into a single sequence.
\[X = \text{concat}(H_q, H_t) \qquad\text{where}\qquad X \in \mathbb{R}^{B \times (N_q + N_t) \times D_q}\]This combined sequence is fed into a standard multi-head self-attention layer. The key is the attention mask (SMS), which controls which tokens can attend to which other tokens.
\[\text{SelfAttn}_\text{output} = \text{MultiHeadSelfAttention}(Q=X, K=X, V=X, \text{Mask}=M)\]The mask $M$ changes depending on the pre-training objective (as seen in Figure 3):
- For ITM (bi-directional): $M$ allows all tokens to attend to all other tokens.
- For ITC (unimodal): $M$ is block-diagonal. $H_q$ can only attend to $H_q$, and $H_t$ can only attend to $H_t$.
- For ITG (multimodal causal): $M$ allows $H_q$ to attend to all $H_q$. It allows $H_t$ to attend to all $H_q$ but only to previous tokens within $H_t$.
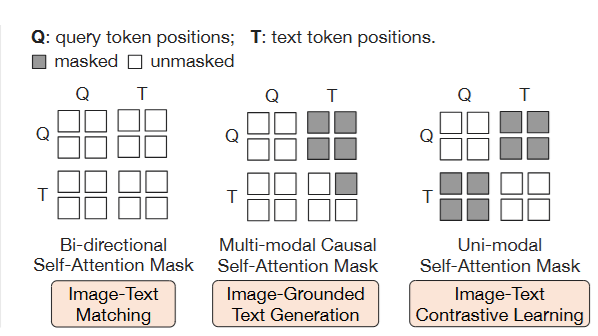
Fig.3 The self-attention masking strategy for each objective to control query-text interaction.
2. Cross-Attention (Injecting Visual Information):
This step only applies to the query representations. The output from the self-attention layer is split back into query and text representations. Let’s call the query part $\text{SelfAttn}_q$.
\[\text{CrossAttn}_q = \text{MultiHeadCrossAttention}(Q=\text{SelfAttn}_q, K=I, V=I)\]The text representations bypass this step entirely. This is crucial: only the queries “see” the image. They act as a bottleneck, summarizing the visual information. The paper notes this happens in every other transformer block.
3. Feed-Forward Network (FFN):
The final step in a block is a standard FFN applied to all representations. The output of cross-attention for queries and the output of self-attention for text are passed through the FFN.
Tokens and Embeddings: The Building Blocks
- Image Tokens: The frozen ViT takes an image, divides it into a grid of patches (e.g., 14x14 pixels), and linearly projects each patch into a vector. These vectors are the image tokens. Positional embeddings are added to retain spatial information.
- Text Tokens: Text is processed using a standard LLM tokenizer (like BPE or WordPiece) into a sequence of sub-word tokens. These are then converted into text embeddings.
- Learnable Query Embeddings: These are the key to the Q-Former. They are a set of $N$ vectors (e.g., $N=32$), each with a dimension $d$ (e.g., $d=768$). They are initialized randomly and are learned during the pre-training process. They are not input-dependent; they are model parameters. Their purpose is to act as a summary or a set of “experts” that learn to extract specific types of visual information (e.g., one query might learn to focus on objects, another on colors, another on textures).
Of course. Let’s break down Stage 1 of the Q-Former’s training in full detail, covering each of the three jointly-optimized tasks with the specifics you requested.
Stage 1 Overview: Vision-Language Representation Learning
The central goal of this stage is to train the Q-Former so that its 32 learnable queries become expert extractors of language-relevant visual information from a frozen image encoder. All three tasks described below are trained simultaneously in a single forward pass, and their losses are summed up to update the Q-Former’s weights.
1. Image-Text Contrastive Learning (ITC)
Mechanics
The goal of ITC is coarse-grained alignment. It teaches the model to recognize which images and texts belong together in a batch, pushing the representations of matching (positive) pairs closer while pushing non-matching (negative) pairs apart in a shared embedding space.
Input-Output Pairs
- Input: A batch of $B$ image-text pairs \(\left\{(I_1, T_1), (I_2, T_2), ..., (I_B, T_B)\right\}\).
- Output: A $B \times B$ similarity matrix, where the diagonal represents positive pair similarities and off-diagonal elements represent negative pair similarities.
Attention Mechanism
- Self-Attention: A unimodal self-attention mask is used. This is critical. The 32 queries and the text tokens are processed in the same transformer, but this mask prevents them from attending to each other. Queries only attend to other queries, and text tokens only attend to other text tokens. This enforces the independent creation of a pure visual representation and a pure textual representation.
- Cross-Attention: Cross-attention happens only for the 32 queries, which attend to the output features from the frozen image encoder. This is how visual information is injected into the queries. The text tokens do not participate in this step.
- Interacting Tokens: Queries interact with image features. Text tokens interact with other text tokens. There is no direct query-text interaction.
Loss Function (with Math)
The loss is the InfoNCE (Noise-Contrastive Estimation) loss, calculated for both image-to-text and text-to-image directions.
-
Representations:
- From the text transformer, we get the
[CLS]token embedding, $t\in \mathbb{R}^{D_q}$. - From the image transformer, we get the 32 output query embeddings, $Z \in \mathbb{R}^{N_q \times D_q}$.
- From the text transformer, we get the
-
Similarity Score $s(I, T)$: The similarity between an image $I$ and text $T$ is defined as the maximum similarity between the text’s
[CLS]vector and any of the 32 query vectors. $s(I, T) = \max_{q \in Z} (\text{sim}(q, t))$ wheresimis the dot product. -
Image-to-Text Loss $\mathcal{L}_{i2t}$: For each image $I_i$, we want to maximize its similarity with the correct text $T_i$ over all other texts $T_j$ in the batch.
\[\mathcal{L}_{i2t} = - \frac{1}{B} \sum_{i=1}^{B} \log \frac{\exp(s(I_i, T_i) / \tau)}{\sum_{j=1}^{B} \exp(s(I_i, T_j) / \tau)}\] -
Text-to-Image Loss $\mathcal{L}_{t2i}$: Symmetrically, for each text $T_i$, we want to maximize its similarity with the correct image $I_i$.
\[\mathcal{L}_{t2i} = - \frac{1}{B} \sum_{i=1}^{B} \log \frac{\exp(s(I_i, T_i) / \tau)}{\sum_{j=1}^{B} \exp(s(I_j, T_i) / \tau)}\]where $\tau$ is a learnable temperature parameter.
-
Total ITC Loss: \(\mathcal{L}_{ITC} = (\mathcal{L}_{i2t} + \mathcal{L}_{t2i}) / 2\)
2. Image-Text Matching (ITM)
Mechanics
The goal of ITM is fine-grained alignment. It’s a binary classification task where the model must determine if a given text truly and accurately describes an image. This forces the model to learn the subtle details connecting visual concepts and words.
Input-Output Pairs
- Input: An image $I$, a text $T$, and a ground-truth label $y \in {0, 1}$. $y=1$ for a positive pair, $y=0$ for a negative pair.
- Output: A single probability $p_{itm} \in [0, 1]$ indicating the likelihood of the pair being a match.
Attention Mechanism
- Self-Attention: A bi-directional self-attention mask is used. This allows for a deep fusion of modalities. Every one of the 32 queries can attend to every text token, and every text token can attend to every query.
- Cross-Attention: Same as ITC: only the 32 queries cross-attend to the frozen image encoder’s features to get infused with visual information.
- Interacting Tokens: Queries interact with image features and with all text tokens. Text tokens interact with other text tokens and with all queries.
Loss Function (with Math)
The loss is a standard Binary Cross-Entropy (BCE) loss.
-
Prediction Score: The 32 output query vectors $Z$, now containing fused multimodal information, are each passed through a linear classifier to produce a logit. These 32 logits are then averaged to get a single final logit \(l_{itm}\). This is converted to a probability $p_{itm}$ via a sigmoid function: \(p_{itm} = \sigma(l_{itm})\).
-
BCE Loss $\mathcal{L}_{ITM}$:
\[\mathcal{L}_{ITM} = - \frac{1}{B} \sum_{i=1}^{B} [y_i \log(p_{itm,i}) + (1 - y_i) \log(1 - p_{itm,i})]\]where $y_i$ is the label for the i-th pair.
Hard Negative Mining
The paper explicitly states it uses the hard negative mining strategy from previous work. For each positive image-text pair, a “hard negative” text is selected from the batch. This is the text that the model thinks is most similar to the image, but is actually incorrect. This forces the model to learn the difficult, fine-grained distinctions.
3. Image-Grounded Text Generation (ITG)
Mechanics
The goal of ITG is to ensure the visual representation learned by the queries is comprehensive enough to be generative. It frames the task as language modeling: predict the text caption, conditioned on the image. This forces the queries to extract all information necessary for description.
Input-Output Pairs
Input: This is the sequence the model receives as context (along with the visual information $I$). It starts with the beginning-of-sequence token ([DEC]) and ends just before the final token.
Input = [DEC], a, black, cat, sits, on, a, red, sofa
output: This is the sequence the model must predict. It starts with the first actual word and ends with the end-of-sequence token ([SEP]).
Target = a, black, cat, sits, on, a, red, sofa, [SEP]
Attention Mechanism
- Self-Attention: A multimodal causal self-attention mask is used. This is designed for autoregressive generation.
- Text tokens can attend to all 32 query tokens to get the visual context.
- Text tokens can only attend to previous text tokens and themselves, preventing them from seeing the future words they need to predict.
- Cross-Attention: Same as before: only the queries cross-attend to the image features.
- Interacting Tokens: Text tokens interact with all queries and with preceding text tokens. Queries interact with image features and all other queries.
Loss Function (with Math)
The loss is a standard autoregressive language modeling loss, which is a Cross-Entropy loss summed over the sequence.
-
Model Probability: The model predicts the next token $T_k$ given the image $I$ (represented by the queries) and the previous ground-truth tokens $T_{<k}$. Let this be $P(T_k \mid I, T_{<k}; \theta)$.
-
Cross-Entropy Loss $\mathcal{L}_{ITG}$:
\[\mathcal{L}_{ITG} = - \frac{1}{B} \sum_{i=1}^{B} \sum_{k=1}^{N_t} \log P(T_{i,k} | I_i, T_{i,<k}; \theta)\]where $N_t$ is the length of the text sequence.
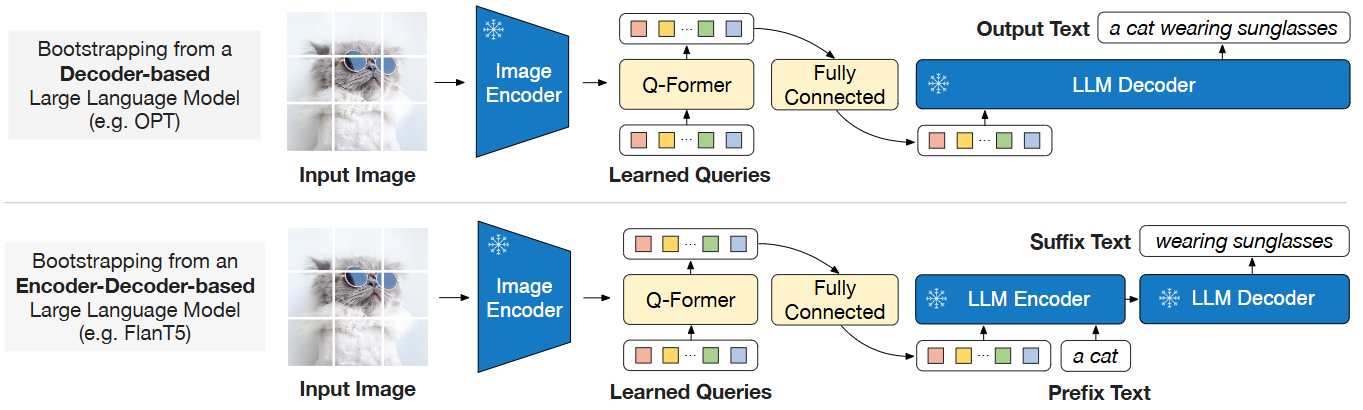
Fig.4 BLIP-2’s second-stage vision-to-language generative pre-training, which bootstraps from frozen large language models (LLMs). (Top) Bootstrapping a decoder-based LLM (e.g. OPT). (Bottom) Bootstrapping an encoder-decoder-based LLM (e.g. FlanT5). The fully-connected layer adapts from the output dimension of the Q-Former to the input dimension of the chosen LLM.
Stage 2: Bootstrap Vision-to-Language Generative Learning from a Frozen LLM.
The goal of this second stage is to connect the vision-aware Q-Former (trained in Stage 1) to a large, powerful, but frozen Large Language Model (LLM). This allows the system to leverage the LLM’s vast knowledge and sophisticated text generation abilities, conditioned on visual input.
Here is the detailed breakdown of Stage 2, based on Section 3.3 and Figure 4 of the paper.
Mechanics
The core idea is to teach the Q-Former to produce visual representations that the frozen LLM can understand as a “prefix” or a “prompt.”
- Architectural Setup:
- The frozen image encoder and the Q-Former (with its weights loaded from the end of Stage 1) are used as a single unit to process the image.
- A frozen LLM is introduced (e.g., OPT for decoder-only models, or FlanT5 for encoder-decoder models).
- A single, simple fully-connected (FC) layer is added. This is the only new trainable component. Its job is to linearly project the output embeddings from the Q-Former to match the input embedding dimension of the chosen LLM.
- Information Flow:
- An image is passed through the frozen image encoder.
- The Q-Former takes the image features and produces its 32 output query vectors ($Z$). These vectors are a compact, language-aligned summary of the image’s content. The -Former at this stage does not receive any textual tokens, since it has already learn the correlation to the textual data in the first stage of training.
- These 32 vectors are passed through the trainable FC layer.
- The resulting vectors are then prepended to the input text embeddings. They now act as soft visual prompts that provide the visual context to the LLM.
- What is Trained?
- Crucially, both the image encoder and the massive LLM remain frozen.
- The parameters of the Q-Former and the newly added FC layer are the only components being trained in this stage. This makes the process highly compute-efficient. The Q-Former’s weights are fine-tuned to adapt its visual output specifically for the LLM it’s paired with.
Task, Loss Function, and Inputs/Outputs
There is only one task in this stage: conditioned language modeling. The model learns to generate a given text caption, conditioned on the visual information provided by the soft visual prompts.
For Decoder-Based LLMs (e.g., OPT)
-
Input: An image $I$ and its corresponding text $T$.
-
Mechanics: The visual prompts from the Q-Former are prepended to the text $T$. The LLM’s task is to autoregressively predict the text $T$, one token at a time, based on the visual prompt and the preceding ground-truth text tokens.
-
Loss Function: A standard autoregressive language modeling loss (Cross-Entropy).
\[\mathcal{L} = - \sum_{k=1}^{N_t} \log P(T_k | Z_{proj}, T_{<k}; \theta_{LLM})\]where $Z_{proj}$ represents the projected query vectors (the soft visual prompt).
For Encoder-Decoder-Based LLMs (e.g., FlanT5)
- Input: An image $I$and its corresponding text
T, which is split into aPrefix Textand aSuffix Text. - Mechanics: The visual prompts ($Z_{proj}$) are concatenated with the
Prefix Textand fed into the LLM’s encoder. The LLM’s decoder is then tasked with generating theSuffix Text. - Loss Function: A prefix language modeling loss (also Cross-Entropy). The loss is calculated only on the generation of the
Suffix Text.
By the end of Stage 2, the Q-Former has learned to effectively “talk” to the frozen LLM, translating images into soft prompts that the LLM can interpret to perform a wide range of instructed, zero-shot, vision-language tasks, as shown in the impressive examples in Figure 5 of the paper.
The goal of this part is to teach the Q-Former to generate a general-purpose visual prompt that an LLM can understand. The task is simple image captioning (e.g., given an image, generate the text “a cat wearing sunglasses”).
Q-Former Input: Image only.
Why? In this phase, the Q-Former doesn’t need any text guidance. Its job is to learn how to summarize an entire image into a soft prompt that the LLM can then use to generate a generic caption. It’s learning the general skill of Image -> Language-aligned Representation.
Down-stream Tasks
Let’s break down how the pre-trained BLIP-2 model is adapted for specific downstream tasks through fine-tuning, and how it’s used for inference in both zero-shot and fine-tuned scenarios.
A. Inference without Fine-tuning (Zero-Shot)
Before diving into fine-tuning, it’s important to understand BLIP-2’s primary strength: instructed zero-shot image-to-text generation. This is the model’s ability to perform novel tasks guided purely by a text prompt, without any further training.
- Mechanics:
- A user provides an image and a text prompt (an instruction).
- The image is processed by the frozen image encoder and the pre-trained Q-Former (from Stage 2) to generate a soft visual prompt.
- This visual prompt is prepended to the user’s text prompt.
- The combined sequence is fed to the frozen LLM (e.g., FlanT5), which then generates the answer autoregressively.
- Example (from Figure 4):
- User Input Image: A photo of a pizza that looks like a cat.
- User Input Prompt: “What is in the photo?”
- LLM Input:
[soft visual prompt from Q-Former]+"What is in the photo?" - Model Output: “A pizza that looks like a cat.”
This zero-shot capability is powerful but can be improved for specific, well-defined tasks through fine-tuning.

Fig.5 Selected examples of instructed zero-shot image-to-text generation using a BLIP-2 model w/ ViT-g and FlanT5XXL, where it shows a wide range of capabilities including visual conversation, visual knowledge reasoning, visual commonsense reasoning, storytelling, personalized image-to-text generation, etc.
B. Fine-tuning on Specific Downstream Tasks
Fine-tuning adapts the pre-trained model to excel at a single, specific task. In all generative fine-tuning tasks below, the core principle is the same: the LLM remains frozen, while other parts of the model are updated.
1. Image Captioning
-
Goal: To generate a high-quality, descriptive sentence for an image.
- Fine-tuning Mechanics:
- What is Trained: The Q-Former and the Image Encoder are fine-tuned. The FC layer connecting them to the LLM is also trained.
- What is Frozen: The LLM.
- Inputs: The Q-Former receives the image only. A generic prompt like
"a photo of"is used as a fixed starting point for the LLM’s text input. - Loss: A standard language modeling loss (cross-entropy) on the ground-truth caption.
- Inference Mechanics:
- The user provides an image.
- The fine-tuned Image Encoder and Q-Former create a visual prompt.
- This prompt is prepended to
"a photo of"and fed to the frozen LLM. - The LLM generates the caption.
2. Visual Question Answering (VQA)
-
Goal: To provide a short, accurate answer to a specific question about an image.
-
Fine-tuning Mechanics:
- What is Trained: The Q-Former and the Image Encoder.
- What is Frozen: The LLM.
- Inputs: This is the key difference. The Q-Former receives both the image AND the text of the question. This allows it to perform question-guided feature extraction, focusing only on the visual information needed to answer the question.
- Loss: A language modeling loss on the ground-truth answer.
-
Inference Mechanics:
-
The user provides an image and a question.
-
Both are fed into the fine-tuned Q-Former, which produces a highly relevant, question-specific visual prompt.
-
This prompt and the question are fed to the frozen LLM.
-
The LLM generates the answer.
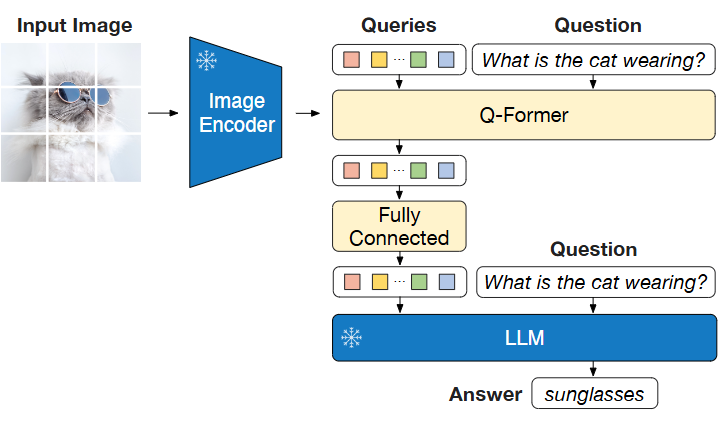
Fig.6 Model architecture for VQA finetuning, where the LLM receives Q-Former’s output and the question as input, then predicts answers. We also provide the question as a condition to Q-Former, such that the extracted image features are more relevant to the question.
-
3. Image-Text Retrieval
- Goal: Given a query (one image or one text), find the best match from a large collection of candidates (texts or images).
- Fine-tuning Mechanics:
- What is Trained: This task does not use the LLM at all. It fine-tunes the first-stage-pretrained model, meaning the Image Encoder and the Q-Former.
- What is Frozen: The LLM is completely absent.
- Inputs: Image-text pairs from a specific retrieval dataset (e.g., COCO).
- Loss: The same three losses from Stage 1 are used together: Image-Text Contrastive (ITC), Image-Text Matching (ITM), and Image-Grounded Text Generation (ITG). This further optimizes the model’s alignment capabilities.
- Inference Mechanics (Two-Step Process):
This process is designed to be both fast and accurate.
- Step 1: Candidate Selection (Fast):
- Given a text query, the model quickly computes a coarse similarity score between the query and all candidate images using the efficient ITC embeddings.
- It selects the top-k most similar images (e.g., k=128) and discards the rest.
- Step 2: Re-ranking (Accurate):
- For each of the top-k candidates, the model performs the more computationally intensive ITM task. This involves deeply fusing the query and candidate image representations to get a highly accurate match score.
- The image with the highest ITM score is returned as the final answer.
- Step 1: Candidate Selection (Fast):
Reference
The work described here is based on the original research paper:
Li, J., Li, D., Savarese, S., & Hoi, S. (2023). BLIP-2: Bootstrapping Language-Image Pre-training with a Frozen Image Encoder and a Frozen Large Language Model. In Proceedings of the 40th International Conference on Machine Learning (ICML).