A Deep Dive into BLIP: The Full Tutorial on Bootstrapping Language-Image Pre-training
The core idea behind BLIP, as presented in the paper, is to address two major limitations in vision-language pre-training (VLP) models. First, existing models were often specialized, excelling at either understanding-based tasks (like image-text retrieval) or generation-based tasks (like image captioning), but not both. Second, these models were typically trained on massive datasets of image-text pairs scraped from the web, which are often noisy and contain irrelevant or inaccurate text descriptions for the corresponding images. The authors of BLIP argue that this “noisy web text is suboptimal for vision-language learning.”
To overcome these issues, BLIP introduces two key innovations:
- A Unified Model Architecture: A flexible model called the Multimodal Mixture of Encoder-Decoder (MED) that can be adapted for both understanding and generation tasks.
- A Data Bootstrapping Method: A technique named Captioning and Filtering (CapFilt) that cleans up and improves the quality of web-scraped datasets. In essence, CapFilt generates new, synthetic captions for images and then filters out the noisy ones, creating a higher-quality dataset for pre-training.
1. Core Intuition: Solving the Noisy Correspondence Problem
The fundamental challenge BLIP addresses is the noisy correspondence in web-scraped image-text pairs. A model trained on pairs like (image_of_a_cat.jpg, "My favorite photo") learns very little.
BLIP’s Core Idea: A model that is already somewhat proficient at vision-language tasks should be able to identify and correct these noisy pairs. This creates a powerful feedback loop:
-
Captioner: The researchers take a pre-trained model and fine-tune it to become a Captioner. This fine-tuning is done on a relatively small, human-annotated dataset. As mentioned in Section 4 of the paper, they use the COCO dataset for this purpose. The goal is to teach the model how to generate high-quality, descriptive captions by showing it examples of them.
Once the Captioner is trained, it is then applied to the massive collection of images from the noisy web datasets (which, in their experiments, contain up to 129 million images). The Captioner generates a new, synthetic caption for each of these web images.
-
Filter: A filter is also fine-tuned on the same high-quality dataset (COCO). Its job is to go through both the original web-scraped captions and the newly generated synthetic captions by the captioner and remove any that are a poor match for the image.
The result is a new, “bootstrapped” dataset that contains a mix of human-annotated pairs and cleaner, more reliable image-text pairs from the web. This higher-quality dataset is then used to pre-train a new BLIP model from scratch, leading to significant performance improvements on a variety of downstream tasks. The paper shows that this process is more effective than simply training for more epochs on the noisy data.
In summary, BLIP’s innovation lies in its unified model architecture that can handle diverse tasks and its data-centric approach of cleaning and augmenting noisy web data to create a more effective pre-training dataset.
This self-supervision process is called bootstrapping, and the mechanism is CapFilt (Captioning and Filtering).
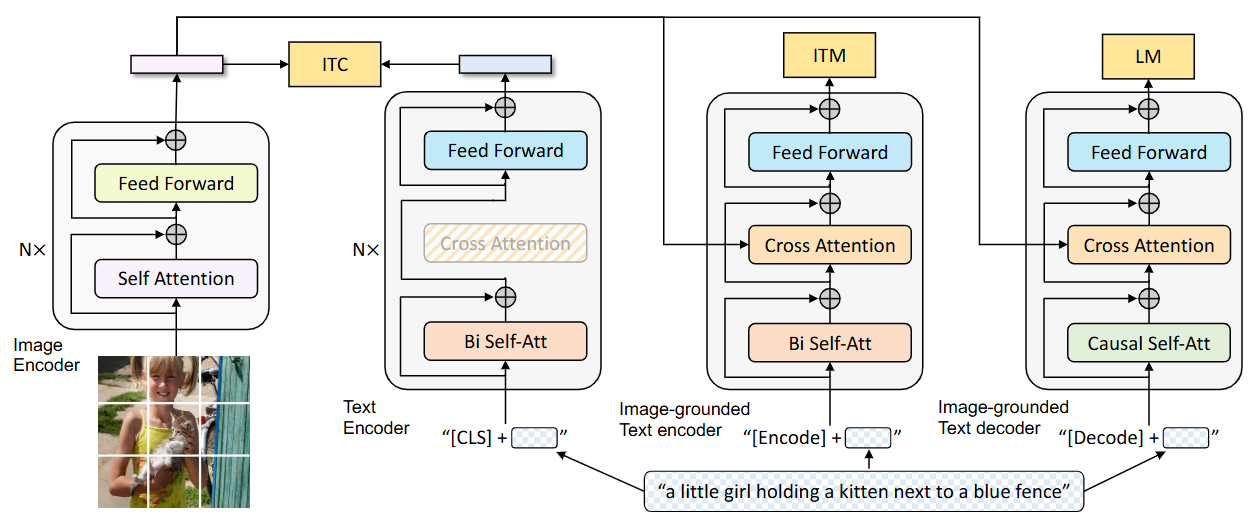
Fig.1 Pre-training model architecture and objectives of BLIP (same parameters have the same color). We propose multimodal mixture of encoder-decoder, a unified vision-language model which can operate in one of the three functionalities: (1) Unimodal encoder is trained with an image-text contrastive (ITC) loss to align the vision and language representations. (2) Image-grounded text encoder uses additional cross-attention layers to model vision-language interactions, and is trained with a image-text matching (ITM) loss to distinguish between positive and negative image-text pairs. (3) Image-grounded text decoder replaces the bi-directional self-attention layers with causal self-attention layers, and shares the same cross-attention layers and feed forward networks as the encoder. The decoder is trained with a language modeling (LM) loss to generate captions given images.
2. Model Architecture: A Trifecta of Functionality
Let’s break down the BLIP model architecture in detail, referencing the components shown in Figure 1.
The architecture is designed around a core principle: unifying vision-language understanding and generation within a single, flexible model. It achieves this through a Multimodal Mixture of Encoder-Decoder (MED), which is not a static structure but a single model that can operate in three different ways depending on the task.
The two main building blocks are:
- Image Encoder: A Vision Transformer (ViT).
- Text Transformer: A transformer that is adapted to form the MED.
Here’s a full breakdown of the components and how they work together.
1. Image Encoder
The image encoder’s job is to convert an image into a sequence of numerical representations (embeddings) that the rest of the model can understand.
- Model Used: BLIP uses a Vision Transformer (ViT), which was pre-trained on ImageNet.
- Process:
- The input image is divided into a grid of fixed-size patches (e.g., 16x16 pixels).
- Each patch is flattened and linearly projected into an embedding.
- A special
[CLS]token is added to the beginning of this sequence of patch embeddings. The final embedding corresponding to this[CLS]token is trained to represent the entire image as a single global feature. - This sequence of embeddings (the
[CLS]token embedding + all patch embeddings) is then processed by the standard Transformer blocks of the ViT.
The output is a set of feature vectors: one global feature ([CLS]) and one feature for each image patch: $E_{img} = {v_{cls}, v_1, v_2, …, v_N}$, where $v_i$ is the feature vector for the $i$-th patch.
2. Multimodal Mixture of Encoder-Decoder (MED)
This is the core innovation of BLIP. It’s a single text transformer model based on BERT that has been modified to operate in three distinct “functionalities” by sharing most of its parameters.
Functionality 1: Unimodal Text Encoder
- Purpose: To encode text separately from the image.
- Architecture: This is essentially a standard BERT model. It takes a text input, adds a
[CLS]token at the beginning, and processes it through its transformer layers to produce contextualized word embeddings. - How it’s Used: This functionality is activated for the Image-Text Contrastive (ITC) loss. The model encodes the text and the ViT encodes the image independently. The resulting
[CLS]embeddings for the image and text are then compared to see how well they align, pushing positive pairs closer in the feature space. This is shown on the left side of Figure 1.
Functionality 2: Image-Grounded Text Encoder
- Purpose: To create a rich, joint representation of an image and a text for understanding tasks, like judging if a caption matches an image.
- Architecture: This mode modifies the text encoder by injecting visual information. In each of the transformer blocks, an extra cross-attention layer is inserted between the self-attention layer and the feed-forward network.
- Cross-Attention Mechanism: In this layer, the text embeddings act as the query, while the image patch embeddings from the ViT act as the key and value. This forces the text representations to “attend to” and incorporate information from the visual features.
- How it’s Used: This is activated for the Image-Text Matching (ITM) loss ($\mathcal{L}_{itm}$). The model is given an image-text pair and predicts whether it’s a “match” or “mismatch”. The final hidden state of a special
[Encode]token is used to make this binary classification.
Functionality 3: Image-Grounded Text Decoder
- Purpose: To generate text based on an image, for tasks like image captioning.
- Architecture: This mode is similar to the Image-Grounded Text Encoder (it also uses cross-attention to see the image), but with one critical difference:
- The standard bi-directional self-attention layers are replaced with causal self-attention layers. This is the defining feature of a decoder (like in GPT). Causal self-attention ensures that when predicting the next word, the model can only look at the words that came before it, not at future words. This is essential for autoregressive text generation.
- How it’s Used: This is activated for the Language Modeling (LM) loss ($\mathcal{L}_{lm}$) . Given an image, the model is trained to predict the next word in the caption. A special
[Decode]token signals the beginning of the text generation process.
Parameter Sharing: The Key to Efficiency and Flexibility
A crucial design choice in BLIP is the parameter sharing strategy within the MED.
- What is shared? The text embedding layer, the cross-attention layers, and the feed-forward networks are all shared across the text encoder and text decoder.
- What is NOT shared? The self-attention layers are unique to the encoder (bi-directional) and the decoder (causal).
The authors argue that the fundamental difference between encoding and decoding lies in the self-attention mechanism, so these are kept separate. Sharing all other parameters makes the model highly efficient, reduces the total parameter count, and allows for effective multi-task learning, as the knowledge gained from one task (e.g., matching) can benefit another (e.g., captioning). Table 3 in the paper shows that this specific sharing strategy yields the best results.
In summary, BLIP’s architecture is a unified framework that uses a ViT for vision and a cleverly designed text transformer (MED) that can flexibly switch between three modes—a standalone text encoder, an image-grounded encoder, and an image-grounded decoder—by leveraging parameter sharing and specialized attention mechanisms. This allows it to be pre-trained on and excel at a wide range of both understanding and generation tasks.
| Function | self-attention Mask | Cross Attention with Image | Use Case |
|---|---|---|---|
| Unimodal Encoder | Bi-Directional | No | Text Embedding |
| Image-Grounded Encoder | Bi-Directional | Yes | Understanding (ITM) |
| Image-Grounded Decoder | Causal | Yes | Generation (LM) |
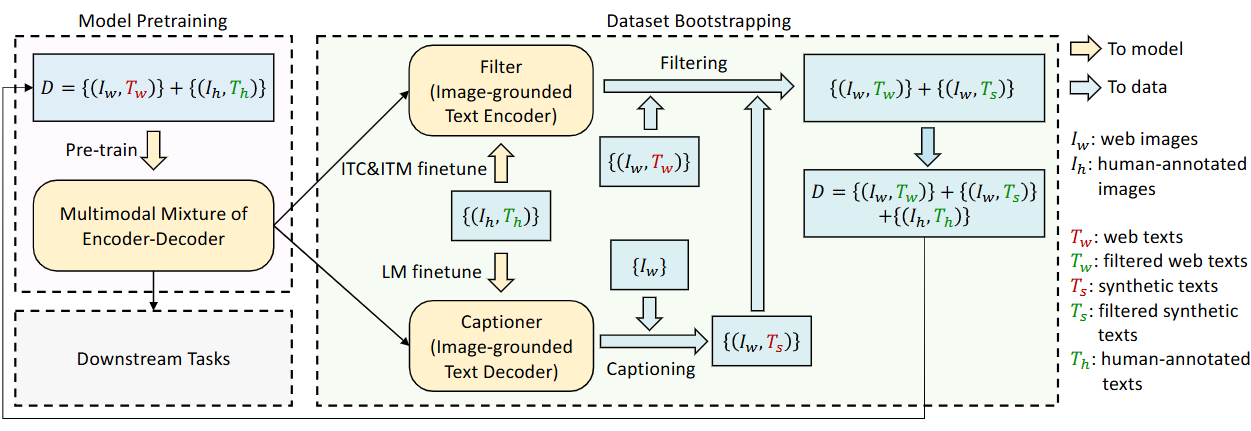
Fig.2 Learning framework of BLIP. A captioner is introduced to produce synthetic captions for web images, and a filter to remove noisy image-text pairs. The captioner and filter are initialized from the same pre-trained model and finetuned individually on a small-scale human-annotated dataset. The bootstrapped dataset is used to pre-train a new model.
3. Pre-training In-Depth: Objectives, Mathematics, and Data Flow
Of course. Let’s dive deep into the training mechanics of BLIP, covering the loss functions, their mathematical basis, the hierarchy of training, and the specific inputs and outputs for each objective.
High-Level Training Objective
The main goal of BLIP’s pre-training is to create a single model that is proficient at three distinct but related vision-language tasks:
- Image-Text Retrieval: Aligning images and texts in a shared feature space.
- Image-Text Matching: Understanding the fine-grained relationship between a specific image and text.
- Image Captioning: Generating relevant text for a given image.
To achieve this, BLIP is trained in a multi-task learning framework where three loss functions, corresponding to these three objectives, are optimized jointly. For each image-text pair in a training batch, the model performs one forward pass through the heavy image encoder (ViT) and three forward passes through the different functionalities of the lighter text transformer (MED), calculating one loss for each.
The Three Pre-training Loss Functions
Here is a detailed breakdown of each loss function, including the math behind it.
1. Image-Text Contrastive (ITC) Loss
-
Objective: To learn a global alignment between image and text features. This loss encourages the embeddings of a matched image-text pair to be closer to each other in the feature space than the embeddings of mismatched pairs.
-
Model Functionality: Unimodal Encoders (Image Encoder and Text Encoder).
-
Input-Output Pairs:
- Input: An image $I$ and a text $T$ from a matched pair.
- Model Output: A normalized image embedding $v(I)$ and a normalized text embedding $t(T)$.
- Target: A “soft” probability distribution created from a momentum encoder, which provides a more stable training signal.
-
The Math Explained: BLIP follows the approach from ALBEF, which uses a momentum encoder and soft-labels for more stable and effective training.
-
Momentum Encoders: There are two sets of encoders. The main encoders (ViT and text encoder) are updated via backpropagation. A second set, the momentum encoders, are not trained directly. Instead, their weights are an exponential moving average of the main encoders’ weights. They provide more stable feature representations ($v^\prime$ and $t^\prime$).
-
Similarity Score: For a batch of N image-text pairs, the similarity between the i-th image and the j-th text is the dot product of their normalized embeddings: $s(I_i, T_j) = v(I_i)^T t(T_j)$.
-
Soft Targets (q): Instead of using a hard “one-hot” label (where only the true pair is a 1), BLIP creates soft target labels using the similarity scores from the more stable momentum encoders. The target probability distribution for the i-th image over all texts in the batch is:
\[q^{i2t}(T_j) = \frac{\exp(s^\prime(I_i, T_j) / \tau)}{\sum_{k=1}^{N} \exp(s^\prime(I_i, T_k) / \tau)}\]Here, $\tau$ is a learnable temperature parameter. $s^\prime$ denotes similarity calculated with momentum features.
-
Model Prediction (p): The model’s predicted probability distribution is calculated similarly, but using the primary encoders:
\[p^{i2t}(T_j) = \frac{\exp(s(I_i, T_j) / \tau)}{\sum_{k=1}^{N} \exp(s(I_i, T_k) / \tau)}\] -
The Loss: The ITC loss is the cross-entropy (H) between the soft target $q$ and the model’s prediction $p$. This is done for both image-to-text ($i2t$) and text-to-image ($t2i$) directions.
\[\mathcal{L}_{ITC} = \frac{1}{2} \mathbb{E}_{(I,T)} [H(q^{i2t}, p^{i2t}) + H(q^{t2i}, p^{t2i})]\]
-
2. Image-Text Matching (ITM) Loss
-
Objective: To learn a fine-grained, multimodal representation that captures the detailed alignment between an image and a text. It’s a binary classification task: does this text truly describe this image?
-
Model Functionality: Image-Grounded Text Encoder.
-
Input-Output Pairs:
- Input: An image $I$ and a text $T$. This can be a positive (matched) or negative (mismatched) pair.
- Model Output: A single probability score $p_{itm}$ indicating the likelihood that the pair is a match.
- Target: A binary label $y_{itm}$ (1 for a match, 0 for a mismatch).
-
The Math Explained:
-
Hard Negative Mining: Creating effective negative pairs is crucial. Instead of using random negatives, BLIP employs hard negative mining. For a given image, it selects a text that the ITC loss found to be a false negative (i.e., a text from a different image that the model thought was a good match). This forces the ITM objective to learn the subtler differences that the ITC objective might miss.
-
Model Prediction: The image-grounded text encoder produces a multimodal embedding for the
[Encode]token. This embedding is fed into a simple linear layer (the “ITM head”) followed by a softmax to produce a probability for the “match” and “mismatch” classes. -
The Loss: The ITM loss is the standard binary cross-entropy loss between the model’s prediction $p_{itm}$ and the ground-truth label $y_{itm}$.
\[\mathcal{L}_{ITM} = \mathbb{E}_{(I,T)} [H(y_{itm}, p_{itm})]\]
-
3. Language Modeling (LM) Loss
-
Objective: To enable the model to generate coherent and contextually relevant text given an image.
-
Model Functionality: Image-Grounded Text Decoder.
-
Input-Output Pairs:
- Input: An image $I$ and its corresponding caption $T$.
- Model Output: A probability distribution over the vocabulary for the next token in the sequence.
- Target: The actual next token in the caption $T$.
-
The Math Explained:
-
Autoregressive Generation: This objective trains the model to predict the next word in a sequence given the image and the preceding words. This is achieved by using a causal self-attention mask in the decoder, which prevents the model from “cheating” by looking at future tokens.
-
The Loss: The LM loss aims to maximize the likelihood of the text caption $T$ given the image $I$. It is a standard cross-entropy loss calculated for each token in the sequence.
\[\mathcal{L}_{LM} = \mathbb{E}_{(I,T)} [-\sum_{i=1}^{|T|} \log p(T_i | T_{<i}, I; \theta)]\]where $T_i$ is the i-th token of the text, $T_{<i}$ are the preceding tokens, and $\theta$ represents the model parameters. The paper also mentions using label smoothing with a rate of 0.1, a common regularization technique.
-
Hierarchy and Overall Training Process
The training process has two main stages:
Stage 1: Dataset Bootstrapping (CapFilt)
This is a preparatory stage to create a high-quality dataset. It is not part of the final model’s training loop but is essential to its success.
- Fine-tune Captioner & Filter: A pre-trained MED model is fine-tuned twice on the small, high-quality COCO dataset:
- Once as a Captioner using the LM objective.
- Once as a Filter using the ITC and ITM objectives.
- Generate & Clean Data:
- The fine-tuned Captioner is used to generate a new synthetic caption for every image in the large, noisy web dataset.
- The fine-tuned Filter then examines both the original web caption and the new synthetic caption for each image. It discards any caption that it scores as a mismatch.
- Final Dataset: The resulting bootstrapped dataset consists of the clean human-annotated pairs (from COCO, etc.) plus the filtered web image-text pairs.
Stage 2: Main Pre-training
A new, randomly initialized BLIP model is pre-trained from scratch on the bootstrapped dataset created in Stage 1.
-
Batch Processing: For each image-text pair $(I, T)$ in a batch:
- The image $I$ is passed through the ViT encoder once.
- The text $T$ is passed through the MED three times, activating each of the three functionalities (unimodal encoder, image-grounded encoder, image-grounded decoder).
-
Loss Calculation: The three losses (\(\mathcal{L}_{ITC}\), \(\mathcal{L}_{itm}\), and \(\mathcal{L}_{LM}\)) are computed as described above.
-
Joint Optimization: The total loss for the model is simply the sum of the three individual losses.
- Backpropagation: The gradients from this total loss are used to update the weights of the ViT and the MED model.
This joint optimization trains all three capabilities of the model simultaneously, resulting in a single, powerful, and flexible vision-language model.
4. The Bootstrapping Engine (CapFilt)
Now we can see how the pre-training objectives power the CapFilt mechanism.
-
Train Initial Model: Train a BLIP model on 14M noisy web images with the combined loss \(\mathcal{L} = \mathcal{L}_{itc} + \mathcal{L}_{itm} + \mathcal{L}_{lm}\). This model is now the “Captioner” and “Filter”. Note that this dataset is noisy but the matching score is human-annotated. So if an image and caption do not match, the model knows.
-
Generate Synthetic Captions (Captioner):
- For each image $I_{web}$ in the dataset: Use the trained Image-Grounded Decoder (\(\mathcal{L}_{lm}\)) to generate a synthetic caption \(T_{synth}\).
- This is a standard beam search decoding process.
-
Filter Noisy Pairs (Filter):
- For each image $I_{web}$: We now have two captions: the original \(T_{web}\) and the synthetic \(T_{synth}\).
- Use the trained Image-Grounded Encoder ($\mathcal{L}_{itm}$) to compute two matching scores:
- The model also has the high-level ITC scores available. The filtering logic uses a combination of these to decide which text to keep. Essentially, if the synthetic text is a much better match for the image than the noisy web text, the web text is discarded.
-
Create Final Dataset and Re-train:
- A new, cleaner “bootstrapped” dataset is created, consisting of all images paired with their filtered, high-quality (often synthetic) captions.
- The BLIP model is trained again from scratch on this cleaner dataset, leading to a much stronger final model.
5. Fine-Tuning on Downstream Tasks
Fine-tuning is the process of taking the pre-trained BLIP model, which has learned general vision-language representations from a massive dataset, and further training it on a smaller, task-specific dataset to specialize it for a particular application.
The core idea is that BLIP’s flexible Multimodal Mixture of Encoder-Decoder (MED) architecture can be rearranged and optimized for different goals. Let’s go through the main downstream tasks mentioned in the paper, detailing the loss, training pairs, and inference process for each.
1. Image-Text Retrieval
- Objective: Given one image, find the most relevant text from a collection of texts (or vice-versa).
- Model Setup: Uses the unimodal encoders (for ITC) and the image-grounded text encoder (for ITM).
- Training (Fine-tuning):
- Input/Output Pairs: The training data consists of
(Image, Caption)pairs from the target dataset (e.g., COCO or Flickr30K). For each pair, the model treats it as a positive example and uses other items in the batch as negative examples. - Loss Function: The model is fine-tuned using the same two understanding-based losses from pre-training: the Image-Text Contrastive (ITC) loss and the Image-Text Matching (ITM) loss.
- $\mathcal{L}_{ITC}$ pushes the global features of matched pairs closer.
- $\mathcal{L}_{ITM}$ teaches the model a more detailed, fine-grained understanding of whether a text truly matches an image.
- Input/Output Pairs: The training data consists of
- Inference (How it’s used):
- Input: A single query (e.g., an image) and a large collection of candidates (e.g., thousands of captions).
- Process (Two-stage): Because running the full ITM model on every candidate is slow, they use an efficient two-stage process:
- Candidate Selection: First, use the fast unimodal encoders (ITC) to quickly calculate the similarity score between the query image and all candidate texts. This produces a ranked list, and the top-k candidates (e.g., k=256) are selected.
- Re-ranking: Second, use the slower but more accurate image-grounded encoder (ITM) to compute a precise matching score for only these top-k candidates. The candidate with the highest ITM score is chosen as the final answer.
2. Image Captioning
- Objective: Generate a textual description for a given image.
- Model Setup: Uses the Image-Grounded Text Decoder.
- Training (Fine-tuning):
- Input/Output Pairs: The input is an
(Image, Caption)pair from the training set. The paper notes they prepend a prompt, such as “a picture of”, to the caption. The model is trained to predict the next word in the caption given the image and all preceding words. - Loss Function: The model is fine-tuned using only the Language Modeling (LM) loss. This is a standard cross-entropy loss that maximizes the probability of generating the ground-truth caption.
- Input/Output Pairs: The input is an
- Inference (How it’s used):
- Input: A single image.
- Process: The model is given the image and the starting prompt (“a picture of”). It then autoregressively generates the caption one word at a time. The paper uses beam search during inference to produce higher-quality, more coherent sentences.
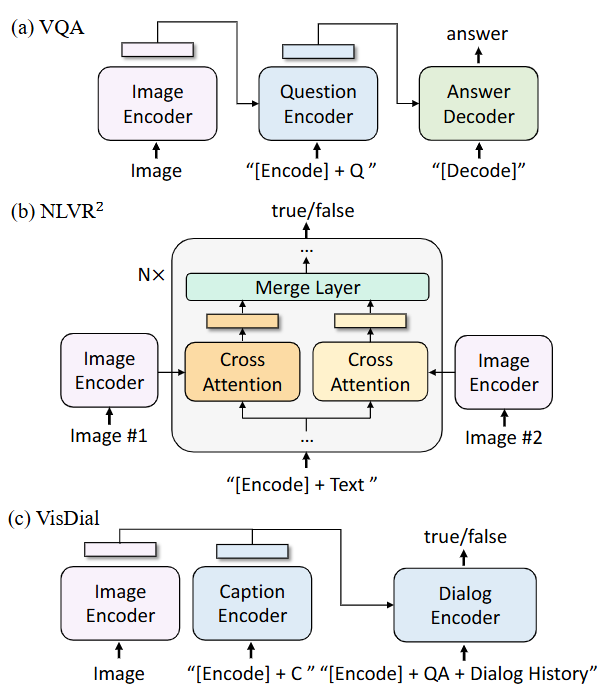
Fig.3 Model architecture for the downstream tasks. Q: question; C: caption; QA: question-answer pair.
3. Visual Question Answering (VQA)
- Objective: Provide a natural language answer to a question about an image.
- Model Setup: This involves a specific rearrangement of the pre-trained model, as shown in Figure 3(a). The model is reconfigured into an encoder-decoder structure where:
- The image and question are encoded together to form a multimodal representation.
- This representation is then fed to a decoder which generates the answer text. This is a key design choice, treating VQA as a generation task rather than a classification task over a fixed set of answers.
- Training (Fine-tuning):
- Input/Output Pairs: The training data consists of triplets:
(Image, Question, Answer). - Loss Function: The model is fine-tuned using the Language Modeling (LM) loss. It is trained to generate the ground-truth answer text given the image and question.
- Input/Output Pairs: The training data consists of triplets:
- Inference (How it’s used):
- Input: An image and a question.
- Process: The model autoregressively generates the answer word by word, just like in image captioning.
4. Natural Language Visual Reasoning (NLVR²)
- Objective: Given a pair of images and a statement, determine if the statement is true or false for that pair.
- Model Setup: This requires another specific modification, shown in Figure 3(b). The image-grounded encoder is adapted to process two images simultaneously. For each transformer block, it has two separate cross-attention layers (one for each image), and their outputs are merged before being passed to the feed-forward network.
- Training (Fine-tuning):
- Input/Output Pairs: The training data consists of
(Image1, Image2, Statement)as input and a binary label(True/False)as the output target. - Loss Function: A binary cross-entropy loss, identical in principle to the ITM loss. An MLP classifier head is placed on top of the final multimodal embedding to predict the True/False probability.
- Input/Output Pairs: The training data consists of
- Inference (How it’s used):
- Input: A pair of images and a statement.
- Process: The model performs a single forward pass and outputs a probability score for “True”.
In summary, the beauty of BLIP’s architecture is its adaptability. For each downstream task, the pre-trained components are used as a powerful starting point, potentially rearranged, and then fine-tuned with a loss function that directly matches the specific goal of that task.
6. Reference
Li, Junnan, Dongxu Li, Caiming Xiong, and Steven Hoi. “BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation.” arXiv preprint arXiv:2201.12086 (2022).